Health Monitoring
Health Monitoring That
Works Out of the Box
Automatic health checks, incident detection, and recovery — without a cloud account or monthly fee.

Automatic health checks, incident detection, and recovery — without a cloud account or monthly fee.
Set custom check intervals, timeouts, and expected status codes for each service. CPI-Control uses smart status mapping — a 404 response means the route exists and the server is healthy, while a 503 or connection timeout means the service is actually down.
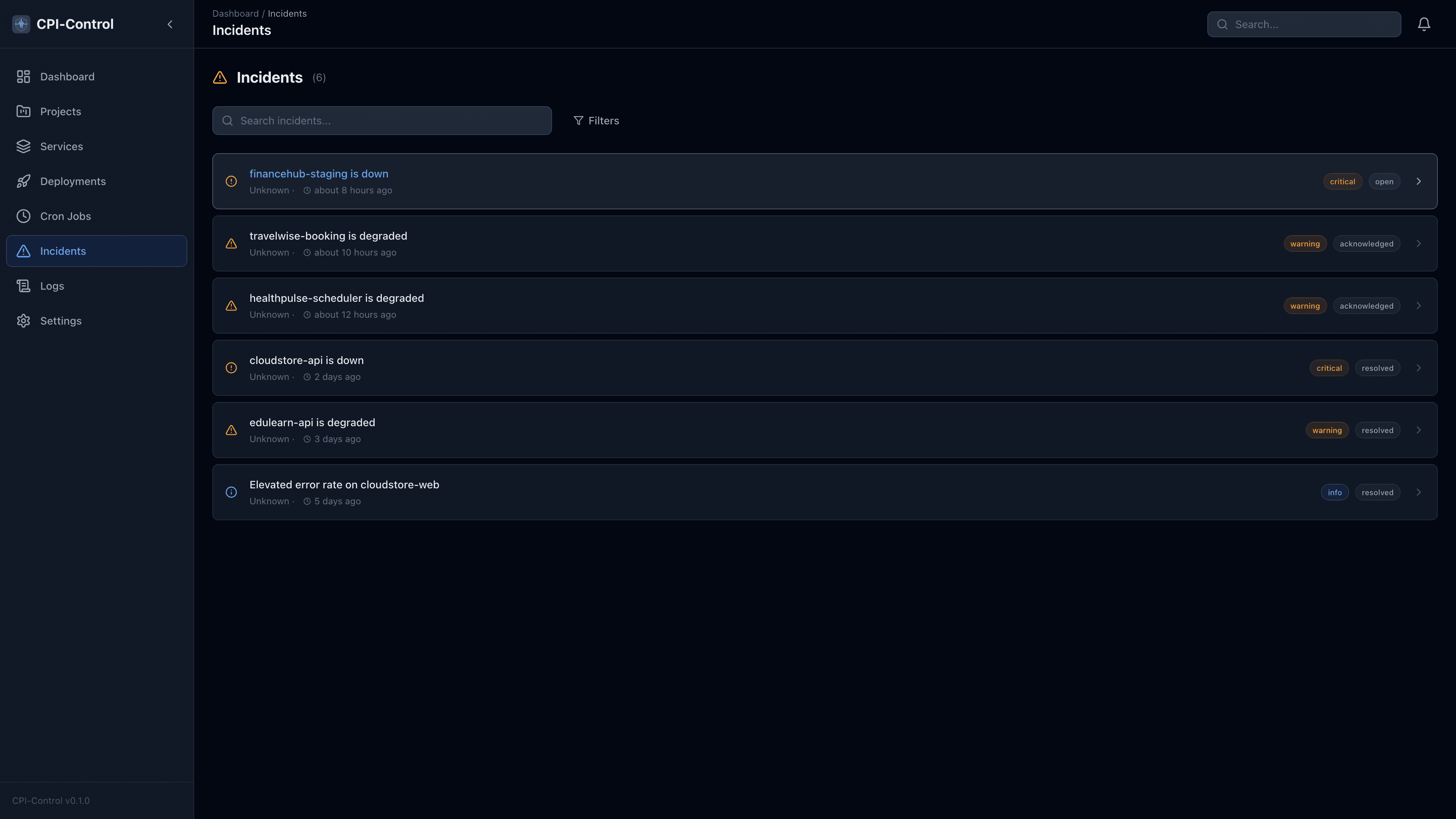
When a health check fails multiple times in a row, CPI-Control automatically creates an incident with full metadata — the HTTP status code, response body, response headers, and the exact timestamp of first failure. No manual incident creation, no missed outages.
When a service comes back online, CPI-Control detects the recovery automatically and resolves the incident. The incident record is updated with the recovery timestamp and total downtime duration. A recovery notification is sent so your team knows the issue is resolved.
api-gateway returned HTTP 503 for 3 consecutive checks
Service returned HTTP 200 — incident resolved automatically
Deploying a big migration? Doing scheduled maintenance? Mute individual services to suppress alerts without disabling monitoring. Choose timed mutes that expire automatically, or permanent mutes that stay until you lift them. No alert storms. No false pages.
Health monitoring is built into CPI-Control. No Pingdom, no UptimeRobot, no additional SaaS subscription. One app, one dashboard, full picture.
All monitoring data stays on your local machine. No health check results are sent to third-party servers. No DPA required.
When a service goes down, you see the latest deployment, the Kubernetes pod status, and the live logs — all in the same app. No tab-switching for context.
Built-in health monitoring for up to 50 services. No cloud account, no credit card, no data leaves your machine. Download and start monitoring in two minutes.